
Can synthetic data help public institutions share data more safely?
Public institutions collect large amounts of data every day. This can include information related to education, employment, mobility, health or social services. When used responsibly, this data can help researchers better understand societal challenges, improve public services and support evidence-based policymaking.
In Luxembourg, it is usually possible to merge these data from different institutions through a shared identifier such as the Matricule Nationale, which allows information from different administrative sources to be connected securely and accurately. At the same time, administrative data often contains sensitive personal information, which means that sharing and reusing it requires strong legal, technical and privacy safeguards.
At Luxembourg National Data Service (LNDS), we worked with the Ministry of Research and Higher Education (MESR) on an initiative exploring whether synthetic data could help support some of these use cases while reducing direct exposure to real personal data. This led to a practical question: can synthetic administrative datasets be linked and analysed in a useful and privacy-conscious way?
Understanding synthetic data
Synthetic data is artificially generated data that resembles real data by preserving relevant internal patterns while masking personal sensitive information. Rather than replicating real individuals, it generates new records that reproduce important patterns in the data.
In theory, this can help researchers and organisations test ideas, develop methods or perform some forms of analysis without directly sharing the original sensitive data.
However, synthetic data is not automatically anonymous, risk-free or suitable for every use case. Its usefulness depends on how it is generated, what type of data is involved and what kind of analysis needs to be performed.
The challenge we explored
The initiative focused on administrative microdata – meaning detailed data about individual records, such as a person, household or organisation.
In many research scenarios, useful insights only emerge when information from different institutions can be combined. For example, researchers may want to study relationships between education, employment and social indicators across datasets held by different public bodies.
MESR initiated this effort to explore how synthetic administrative data could support research and development, particularly when combining data from multiple public institutions. One of the key challenges in this field is measuring both the usefulness of synthetic data and the privacy risks associated with it in practice.
LNDS and MESR teams therefore explored whether separate synthetic datasets could be generated independently and then linked together again in a meaningful way for analysis, similarly to how real datasets may be connected through a shared identifier, such as Luxembourg’s Matricule Nationale.
More specifically, we investigated whether this process could preserve enough statistical utility for research purposes while keeping privacy risks under control.
Exploring two approaches to synthetic data linkage
The initiative consisted of two complementary projects led by LNDS.
The first phase of our collaboration was to assess the work done by a third party. The work began by splitting the original dataset into two parts, generating synthetic versions of each, and then attempting to merge them back together. The assessment focused on whether this process preserved key relationships between variables while maintaining data utility and limiting privacy risks.
The second part of the initiative explored whether another statistical method, Propensity Score Matching (PSM), could be used as an alternative way to reconnect synthetic datasets.
PSM is normally used in research to compare groups with similar characteristics and reduce statistical bias. In this specific case, however, the method did not produce reliable record-level matching results. Because the two datasets originated from the same underlying population and were statistically very similar, the algorithm could not identify enough meaningful differences between records to create reliable one-to-one matches.
Although this approach was not suitable for this particular use case, the investigation still provided valuable insight into the conditions required for synthetic data linkage methods to work effectively. Understanding the implications of linkage methods in raising attention to some feature combinations is also part of the risk assessment analysis, and the remaining utility of still being able to ask the relevant question is the key conclusion in evaluating the end-to-end process reliability.
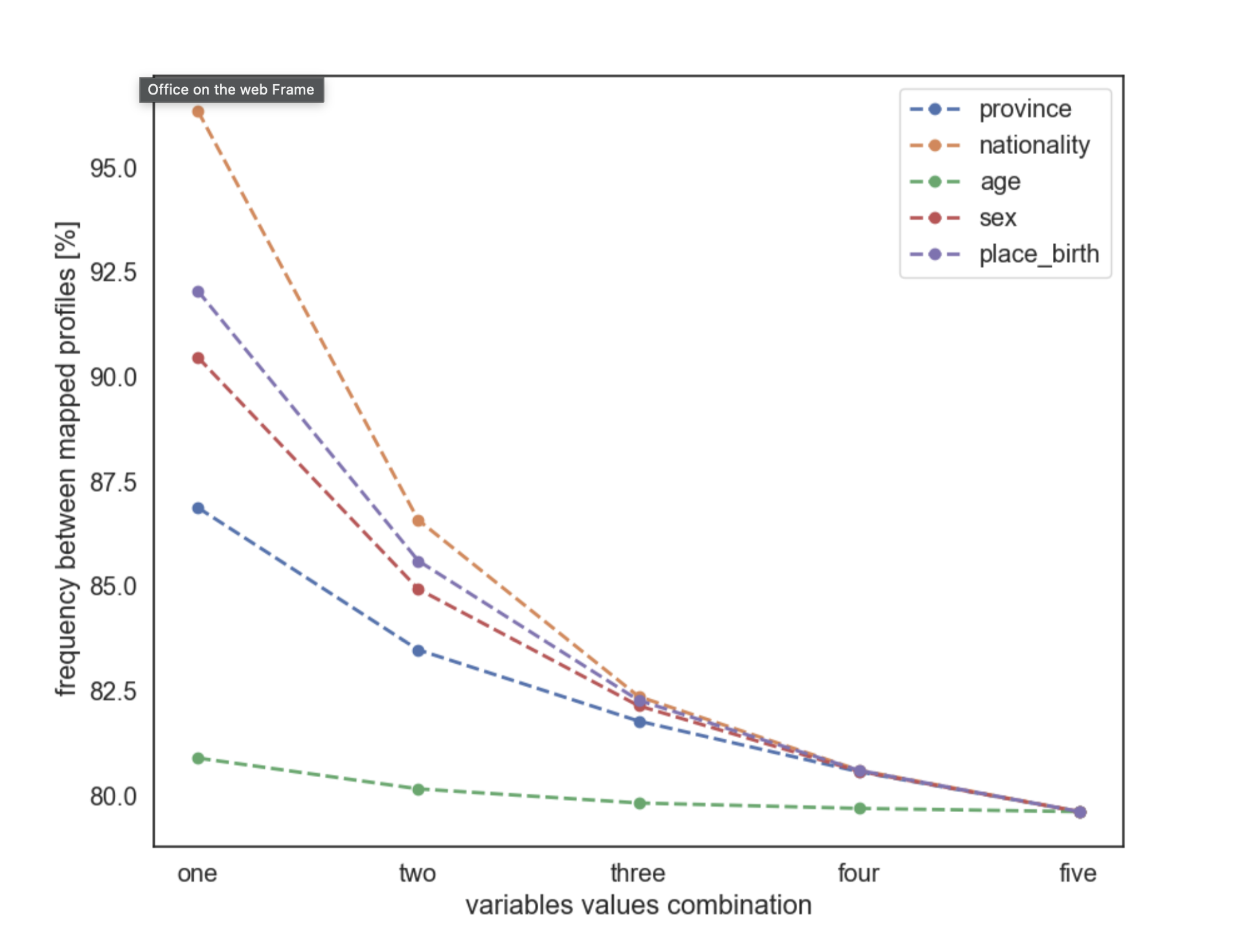
Supporting further analysis
As part of the initiative, we also developed reusable Python scripts to support independent evaluation and additional analysis.
These tools help:
- analyse how variables influence the linkage process,
- evaluate privacy and utility indicators,
- reconstruct datasets after linkage,
- and support experimentation with alternative approaches.
The objective was not only to study a single method, but also to contribute practical tools and lessons learned for future research on synthetic data and privacy-preserving data reuse.
What we learned
Synthetic data is receiving growing attention internationally as organisations look for ways to support research and innovation while reducing privacy risks.
Our work with MESR showed that synthetic data can provide value in several contexts, particularly for experimentation, testing, methodological development and certain forms of collaborative analysis. At the same time, the initiative confirmed that synthetic data works best when designed for a clearly defined purpose and evaluated within the context of a specific use case. Different use cases require different approaches, and both privacy protection and analytical utility need to be evaluated carefully on a case-by-case basis.
One important finding was that privacy and utility need to be assessed together. A dataset may appear useful from a statistical perspective but still require careful evaluation of disclosure risks. Similarly, strong privacy protection may reduce the usefulness of the data for certain analytical tasks.
Another key lesson is the importance of benchmarking. Before evaluating linkage on synthetic data, it is important to understand how the linkage method performs on the original split data. Without this baseline, it becomes difficult to know whether poor results come from the linkage method, the synthetic data generation process, or the characteristics of the dataset itself.
The initiative also reinforced the importance of trusted governance frameworks for data reuse. In some situations, synthetic data may support experimentation, testing or early-stage collaboration, while in others, secure access to real data within controlled environments may remain the most reliable approach for producing robust research outcomes.
A practical contribution to future data reuse
This initiative helped build practical understanding around how synthetic data could support trusted data reuse in Luxembourg’s public sector ecosystem.
For MESR, the project provided concrete insights into the opportunities and limitations of using synthetic administrative data for research and analysis across institutions.
For LNDS, the initiative contributed to ongoing work around privacy-preserving data reuse, secure data processing and trustworthy data services.
More broadly, the work demonstrated that synthetic data can support experimentation, testing and methodological development while reducing direct exposure to sensitive personal data. At the same time, it reinforced the importance of evaluating privacy protection and analytical usefulness together, depending on the intended use case.
The project also highlighted the continued importance of trusted governance frameworks for data reuse. In some scenarios, synthetic data may support early-stage exploration or collaboration, while in others, secure access to real data within controlled environments may remain the most reliable approach for producing robust research outcomes. This balanced understanding is essential for developing realistic and responsible approaches to data reuse in practice.
Looking ahead
The work with MESR helped clarify where synthetic data can add value, and where further research and validation are still needed.
At LNDS, we continue exploring practical approaches for trusted data reuse, including synthetic data generation, privacy-preserving linkage methods and secure data processing environments. The objective is not simply to make data easier to share, but to better understand how different technical and governance approaches can support responsible, secure and useful data reuse in practice.
Through initiatives like this one, we aim to contribute to a more informed and realistic understanding of both the potential and the limitations of synthetic data in research and public sector collaboration.